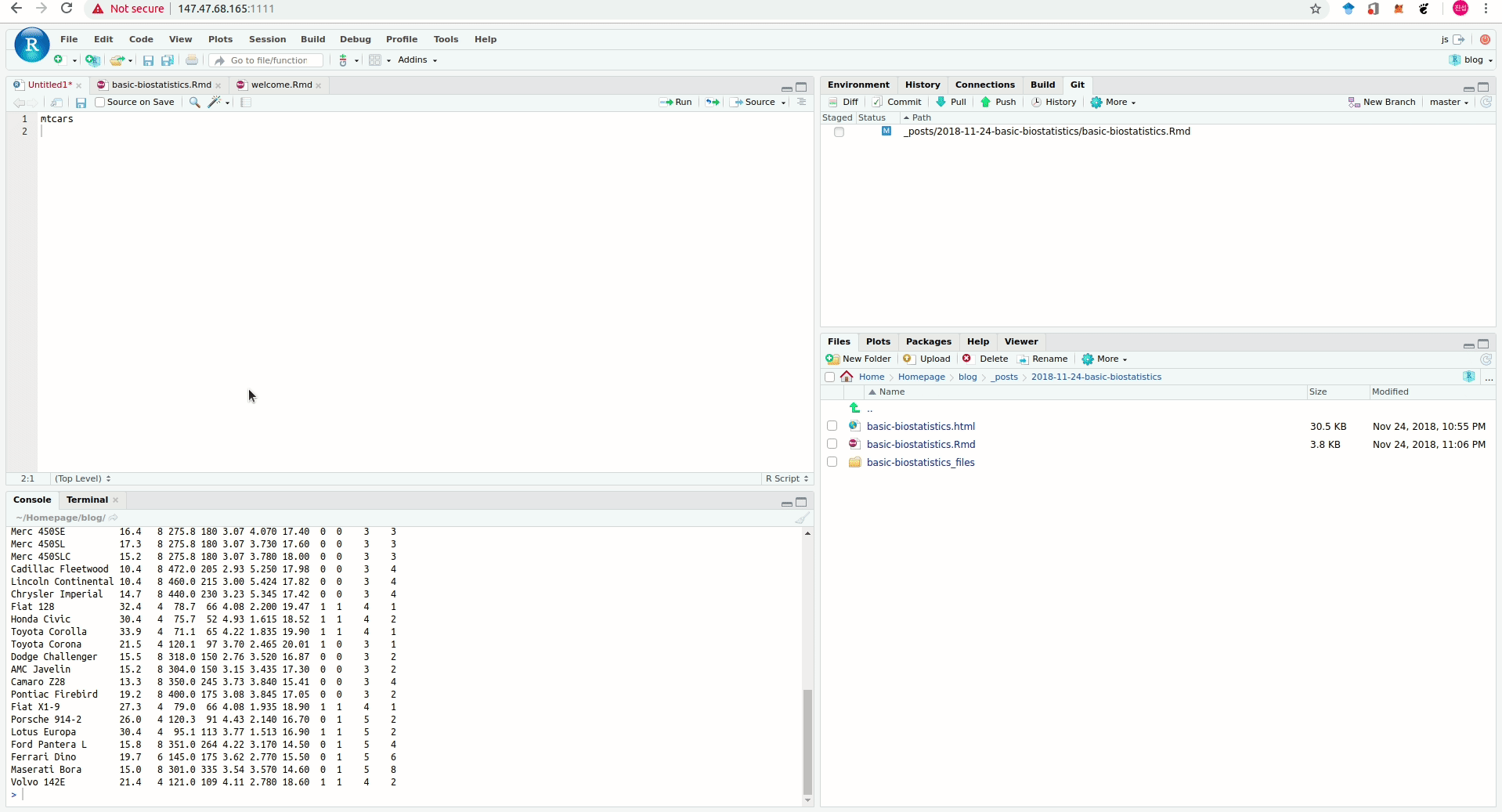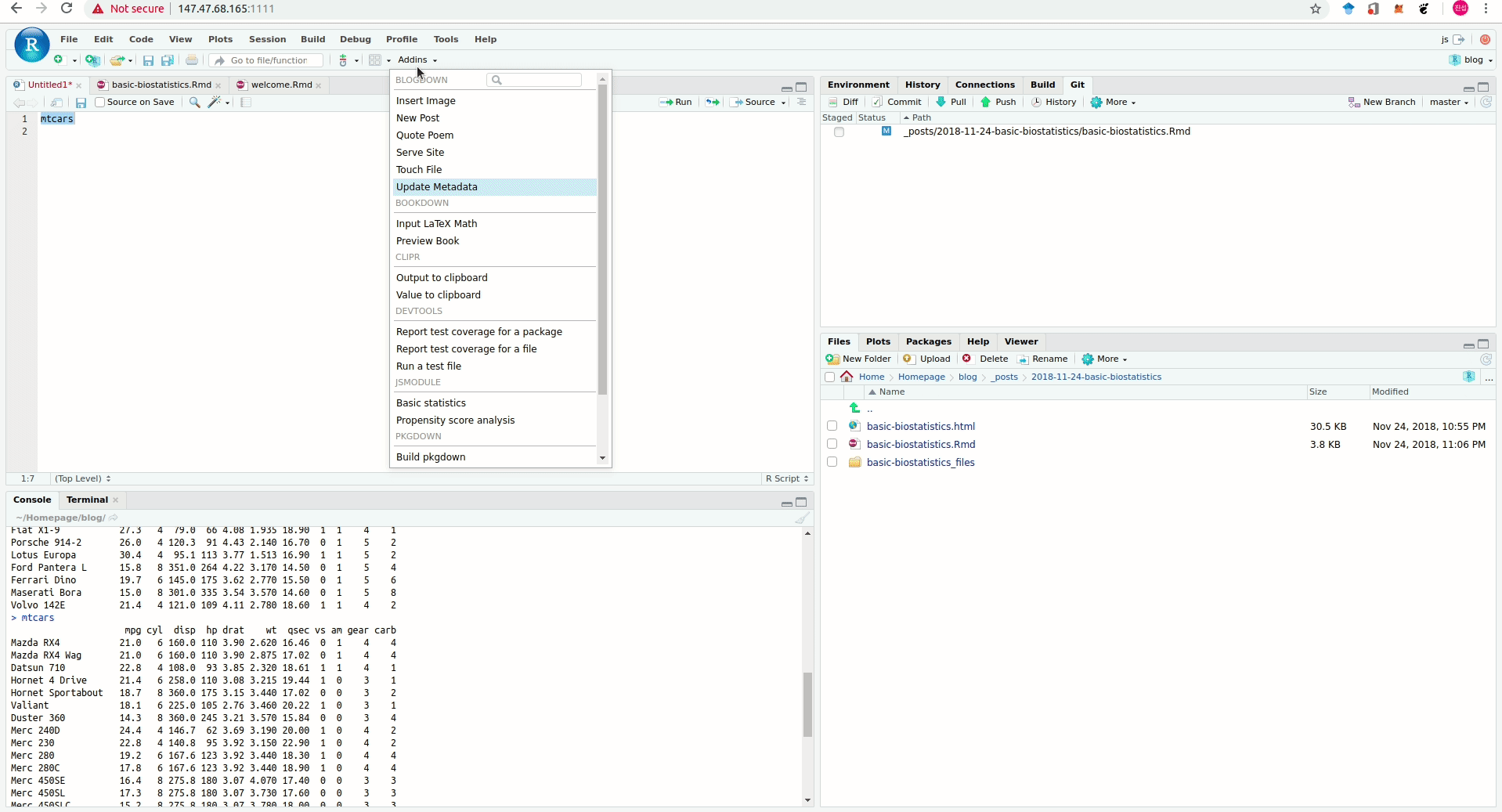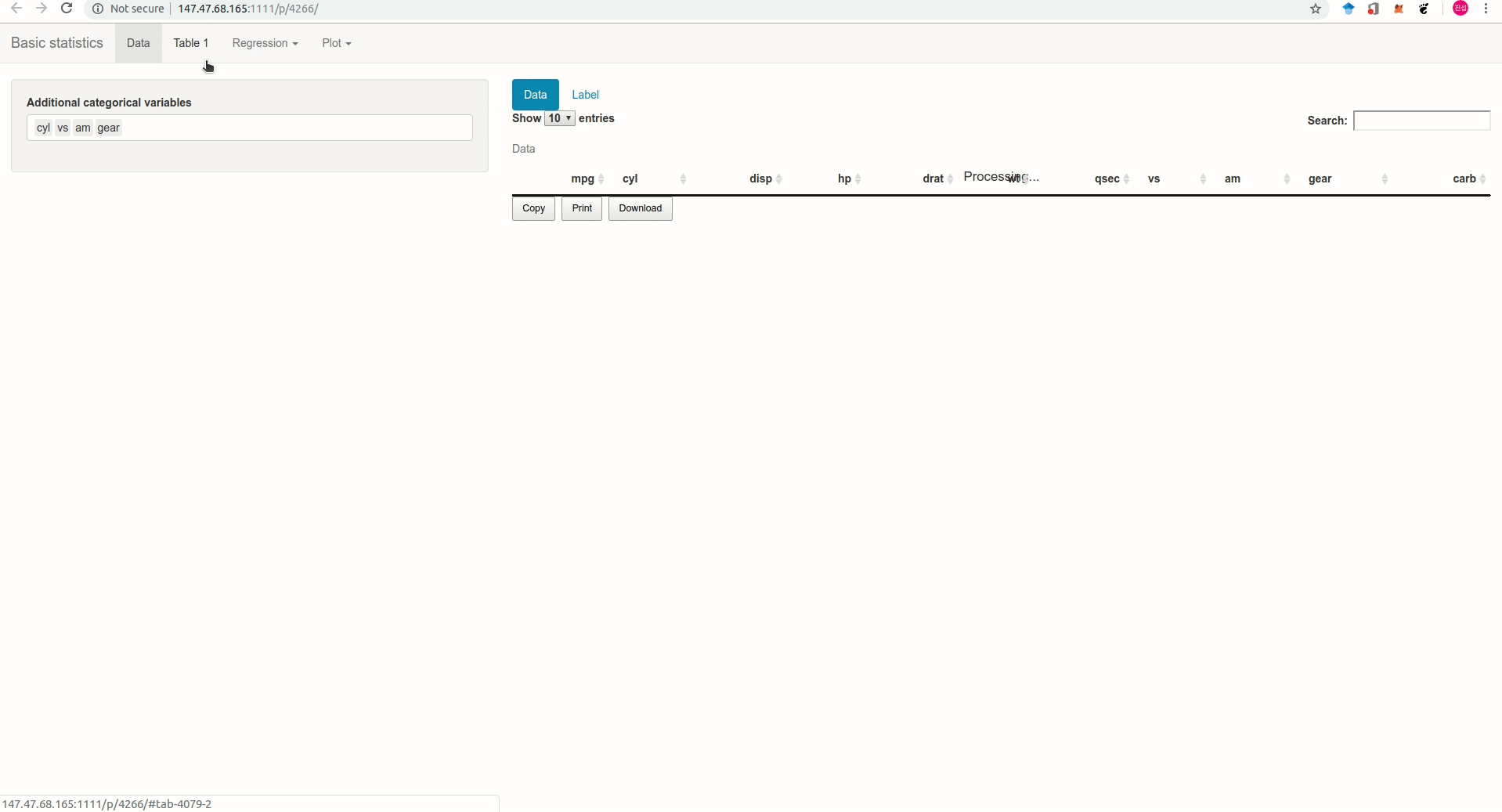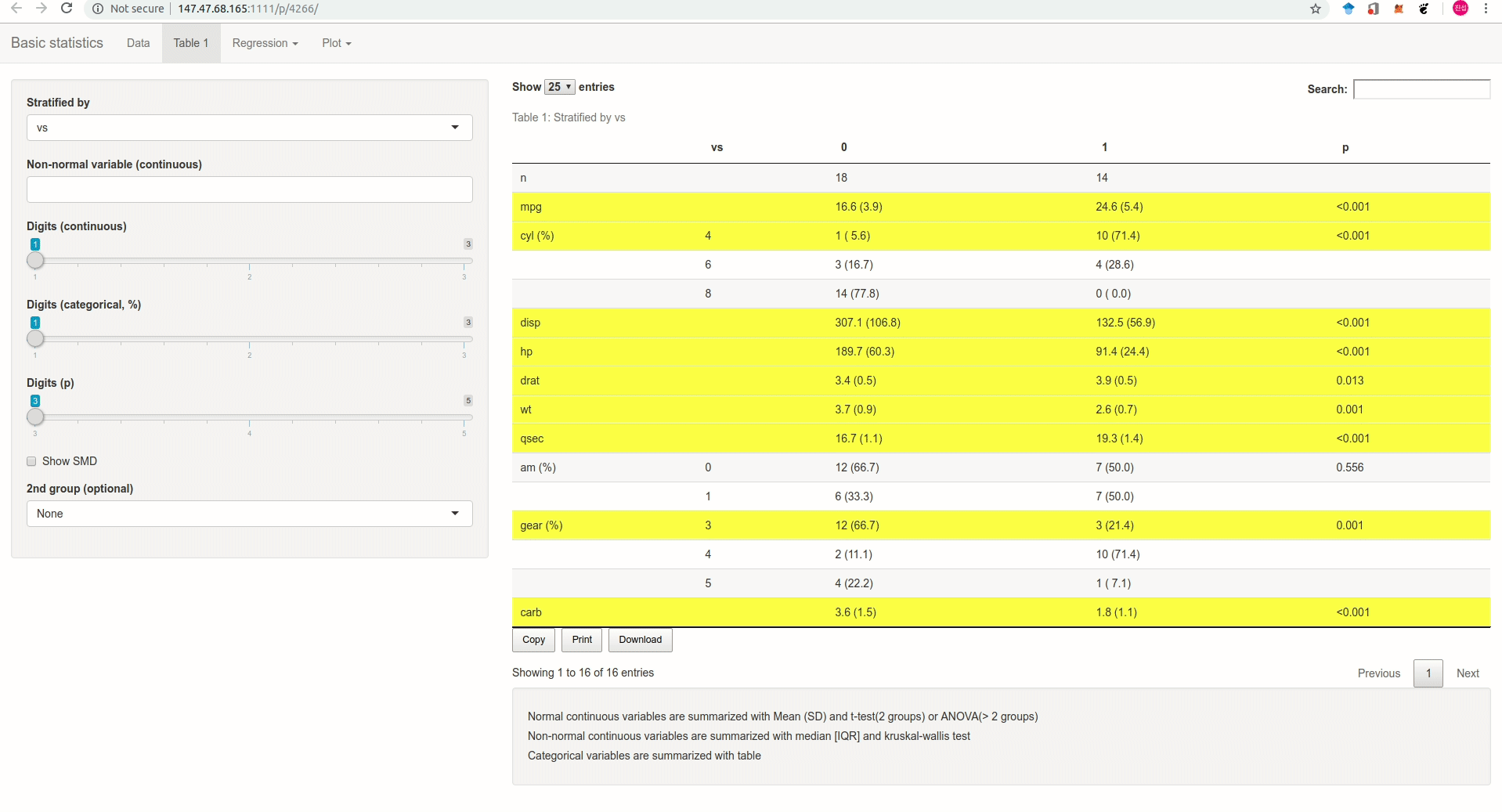
nev.ttest <-t.test(tChol ~ sex, data = data.t, var.equal = F)nev.ttest
Welch Two Sample t-test
data: tChol by sex
t = -1.2857, df = 7.975, p-value = 0.2346
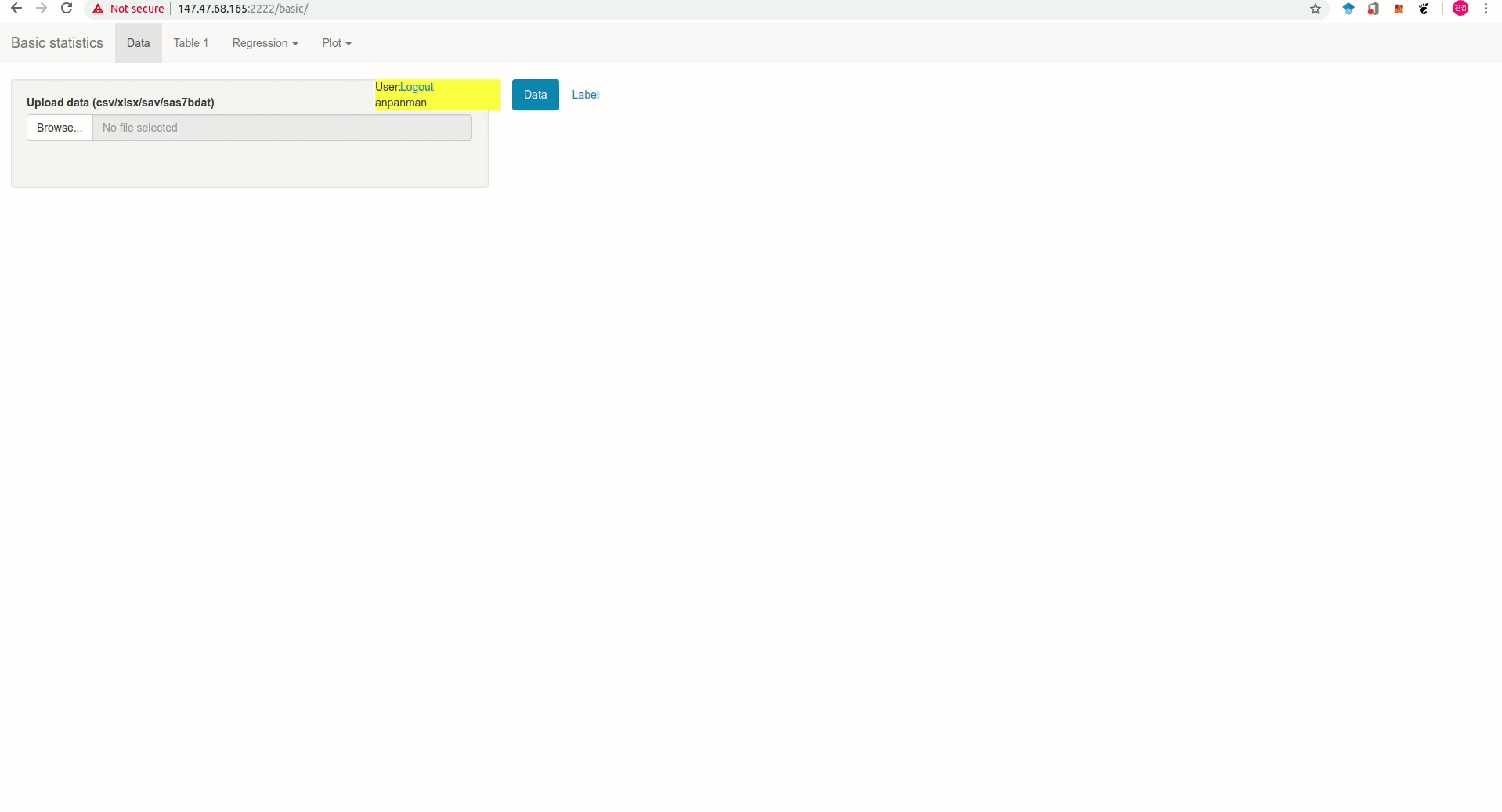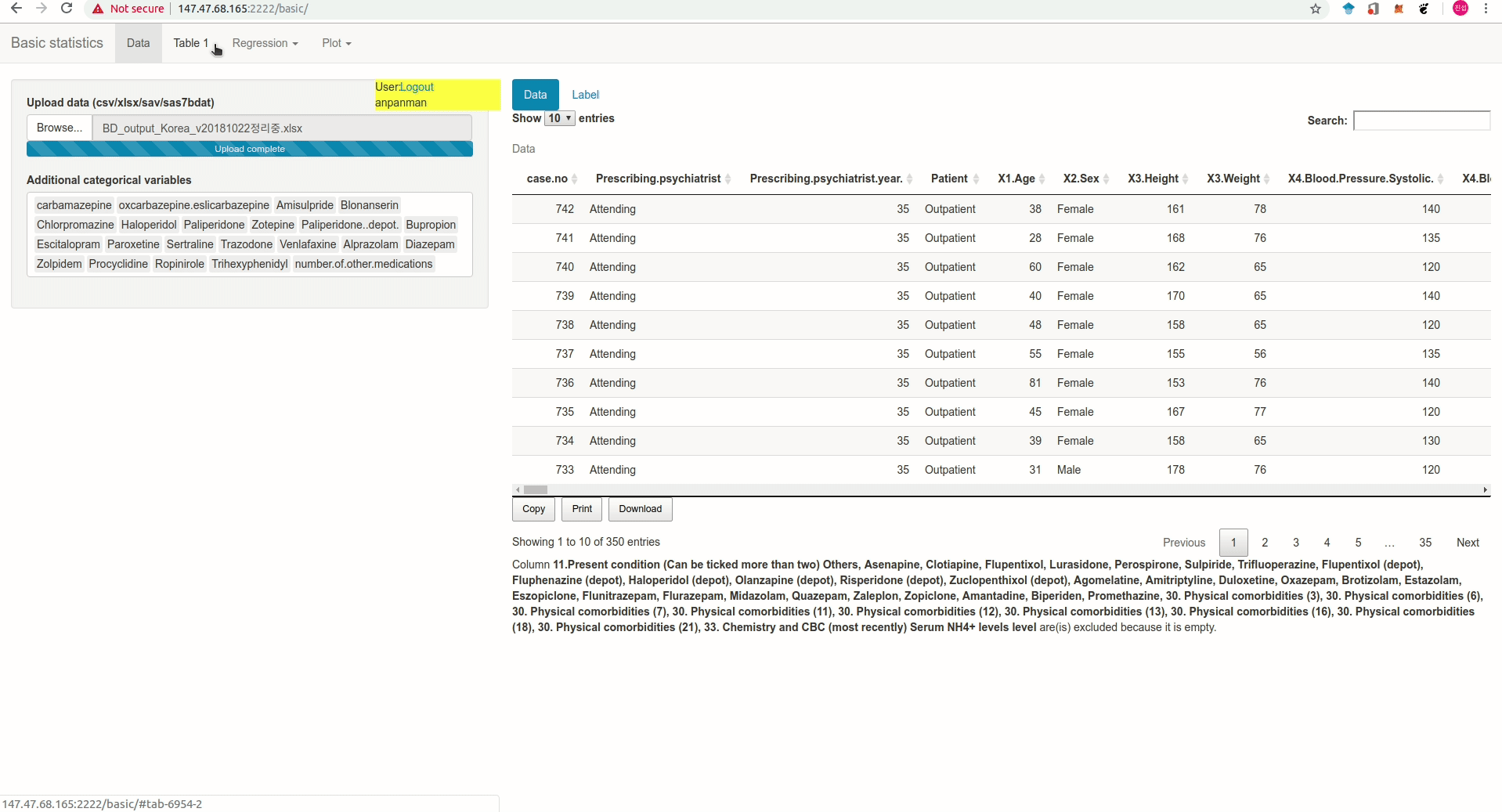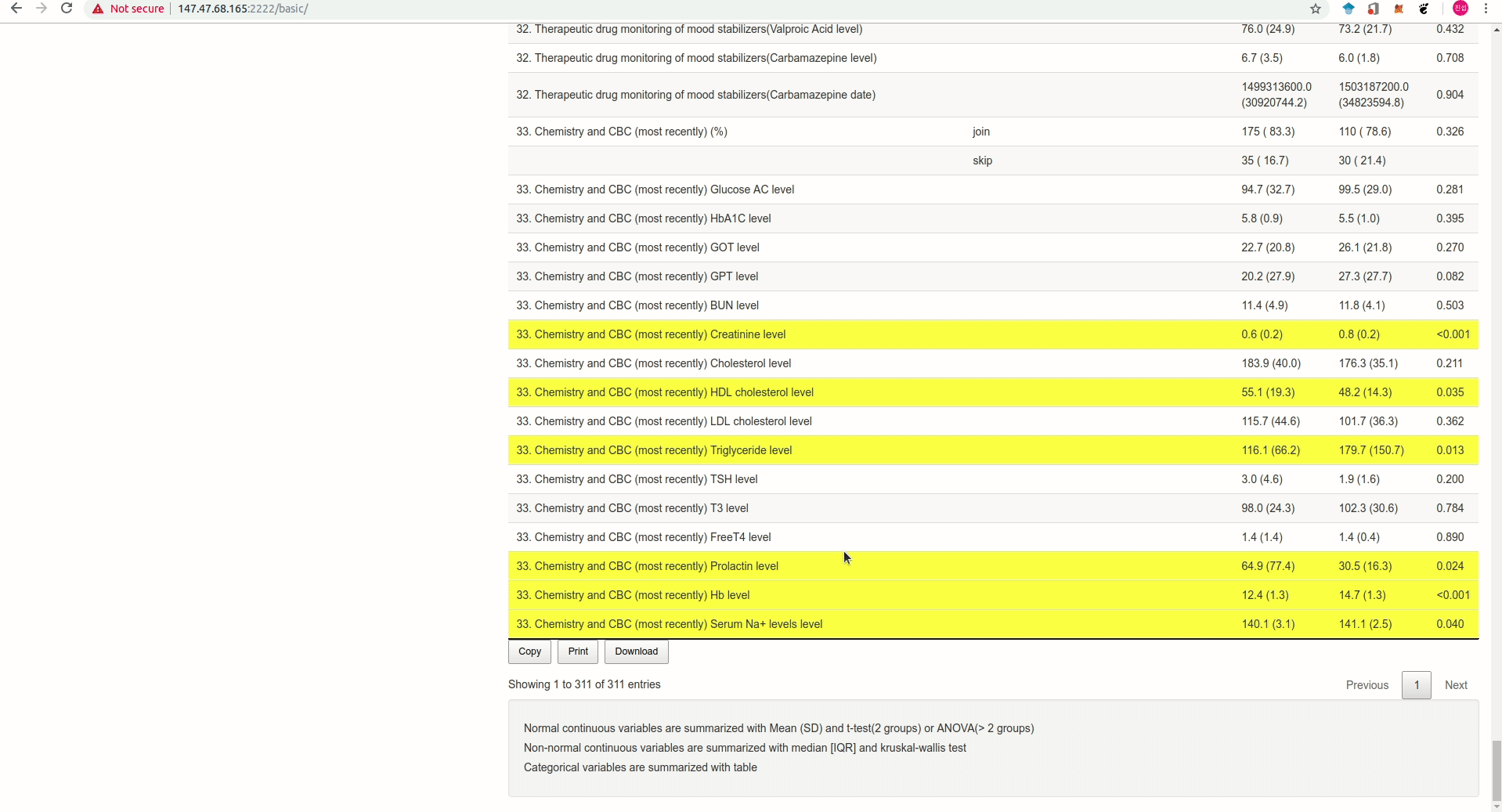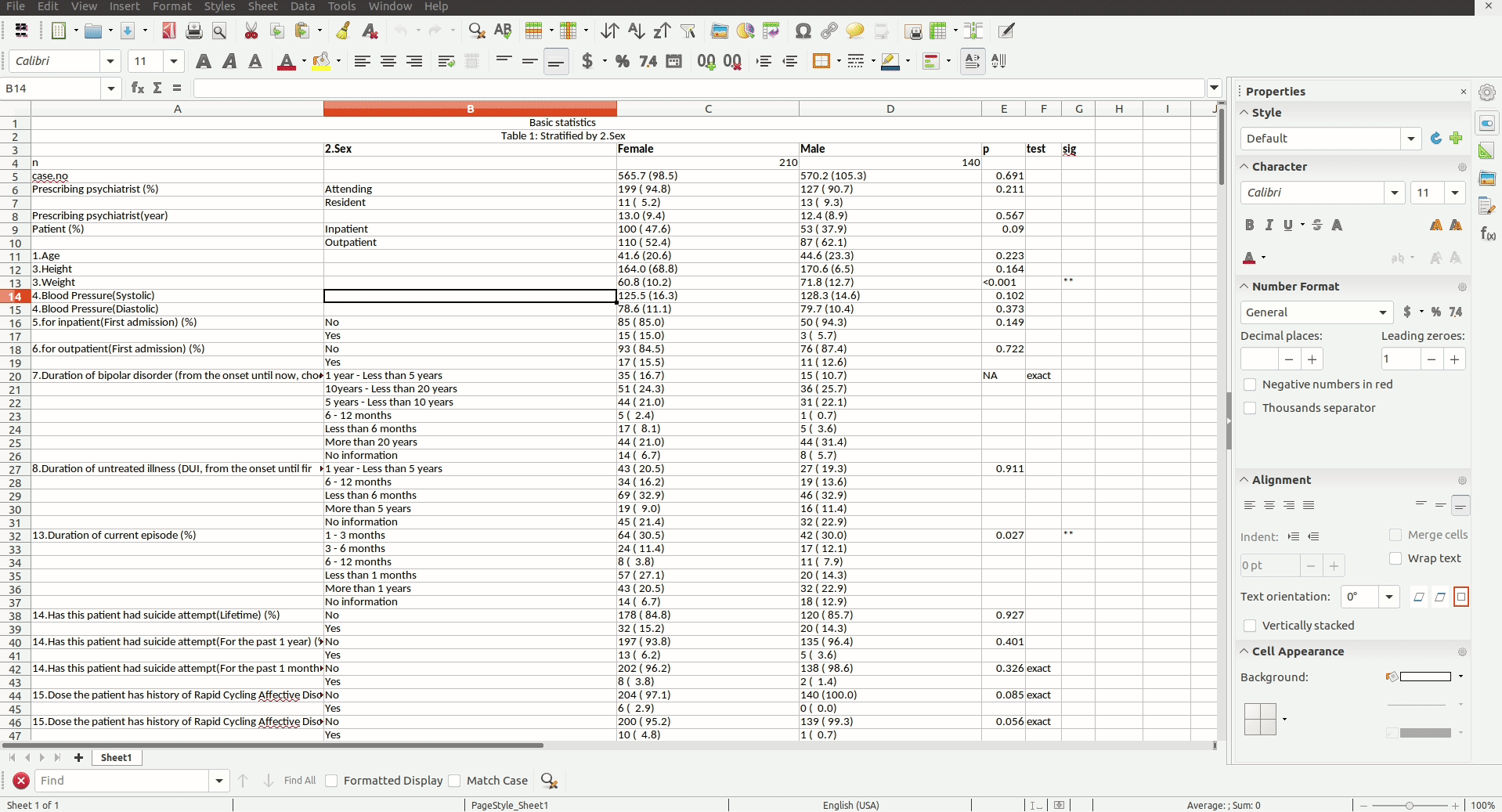
alternative hypothesis: true difference in means between group Female and group Male is not equal to 0
95 percent confidence interval:
-50.71956 14.42143
sample estimates:
mean in group Female mean in group Male
132.5652 150.7143
여자의 평균 콜레스테롤 값은 132.6, 남자는 150.7 이고 p-value는 0.235
var.equal = F는 등분산 가정 없이 분석하겠다는 뜻. 등분산 가정이란 두 그룹의 분산이 같다고 가정하는 것인데, 계산이 좀 더 쉽다는 이점이 있으나 아무 근거 없이 분산이 같다고 가정하는 것은 위험한 가정이다.
t-test 4
ev.ttest <-t.test(tChol ~ sex, data = data.t, var.equal = T)ev.ttest
Two Sample t-test
data: tChol by sex
t = -1.5389, df = 28, p-value = 0.135
alternative hypothesis: true difference in means between group Female and group Male is not equal to 0
95 percent confidence interval:
-42.30638 6.00824
sample estimates:
mean in group Female mean in group Male
132.5652 150.7143
앞서는 Welch t-test 였는데 이름이 바뀐 것을 확인할 수 있고 p-value도 0.135로 다름. - 특별한 경우가 아니고서야 위험한 등분산가정을 할 필요가 없음.
R 에서 디폴트도 F 임.
2그룹에서 ANOVA 하면 (등분산 가정한) t-test와 동일.
등분산 가정없는 ANOVA 도 있음.
library(ggpubr)ggarrange(ggboxplot(data.t, "sex", "tChol", fill ="sex"),ggbarplot(data.t, "sex", "tChol", fill ="sex", add ="mean_sd"))
res.wilcox <-wilcox.test(tChol ~ sex, data = data.t)res.wilcox
Wilcoxon rank sum test with continuity correction
data: tChol by sex
W = 53.5, p-value = 0.1935
alternative hypothesis: true location shift is not equal to 0
ggboxplot(data.t, "sex", "tChol", fill ="sex") +stat_compare_means(method ="wilcox.test")
3그룹 이상: One-way ANOVA
3 그룹 이상의 평균 비교
2그룹씩 짝을 지어서 t-test를 반복할 수도 있으나, Table 1은 보통 하나의 p-value만 제시함.
전체적으로 튀는 것이 하나라도 있는가?를 테스트하는 ANOVA.
어떤 그룹이 차이나는지는 관심없음.
사후(post-hoc) 분석을 이용, 어떤 것이 튀는지를 알아볼 수도 있다.
보통 우리가 쓰는 ANOVA는 비교할 모든 그룹에서 분산이 같다는 등분산 가정 하에 분석을 수행하며, 실제로 2 그룹일 때 ANOVA를 수행하면 등분산 가정 하에 수행한 t-test와 동일한 결과를 얻는다.
물론 등분산 가정없는 generalized ANOVA 도 있고 본사는 이것을 디폴트로 사용한다.
anova 2
anova 3
res.aov1 <-oneway.test(tChol ~ group, data = data.aov, var.equal = F)res.aov1
One-way analysis of means (not assuming equal variances)
data: tChol and group
F = 1.0772, num df = 2.000, denom df = 16.207, p-value = 0.3637
res.aov2 <-oneway.test(tChol ~ group, data = data.aov, var.equal = T)res.aov2
One-way analysis of means
data: tChol and group
F = 0.57761, num df = 2, denom df = 27, p-value = 0.568
등분산 가정없는 p-value인 0.364를 이용하며, 의미는 “3 그룹에서 총콜레스테롤 값이 비슷하다 (다른 것이 있다고 할 수 없다)” 이다.
ggboxplot(data.aov, "group", "tChol", fill ="group", order =c("A", "B", "C")) +stat_compare_means(method ="anova")
혈압약과 당뇨약을 모두 복용한 사람이 2명으로 좀 작아보이지만 무시하고 chi-square test를 수행하면 결과는 나오나 Warning 메시지가 뜬다.
chisq.test(tb.fisher)
Warning in chisq.test(tb.fisher): Chi-squared approximation may be incorrect
Pearson's Chi-squared test with Yates' continuity correction
data: tb.fisher
X-squared = 4.5971e-31, df = 1, p-value = 1
두 약을 모두 복용한 사람이 2명뿐, 분석할 테이블에서 샘플 수가 너무 작은 항이 있으면 chi-square test의 계산이 부정확해진다.
fisher 4
fisher’s exact test 를 해 보자.
res.fisher <-fisher.test(tb.fisher)res.fisher
Fisher's Exact Test for Count Data
data: tb.fisher
p-value = 1
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.07627205 5.55561549
sample estimates:
odds ratio
0.8636115
p-value는 1, 마찬가지로 혈압약 복용과 당뇨약 복용은 유의한 관계가 없다고 할 수 있다.
의문: 무조건 fisher’s test만 하면 간단한데chi-square test는 왜 하나?
샘플 수가 작을 때는 fisher’s test만 하는 것이 실제로 더 간단하고 방법론적으로도 아무 문제가 없다. 그러나 샘플 수나 그룹 수가 늘어날수록 fisher’s test는 계산량이 급격하게 증가한다. chi-square test를 먼저 수행하는 것을 권유한다.
연속변수의 짝지은 그룹비교
Paired t-test
2그룹 : Paired t-test
각 사람의 혈압을 한 번은 사람이 직접, 한 번은 자동혈압계로 측정했다고 하자. 이 때 직접 잰 혈압과 자동혈압계의 측정값을 비교한다면 t-test로 충분할까?
t-test는 혈압 재는 방법마다 평균을 먼저 구한 후 그것이 같은지를 테스트하므로 짝지은 정보를 활용하지 못한다.
각 사람마다 두 혈압값의 차이를 먼저 구한 후 평균이 0인지를 테스트하면, 짝지은 정보를 활용하면서 계산도 더 간단한 방법이 된다.
Welch Two Sample t-test
data: data.pt$SBP_hand and data.pt$SBP_machine
t = -0.45768, df = 57.863, p-value = 0.6489
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3.224307 2.024307
sample estimates:
mean of x mean of y
125.0 125.6
각 방법의 평균을 먼저 구한 후 차이를 비교 했고, p-value는 0.649이다. 이제 paired t-test를 수행하자.
Paired t-test
data: data.pt$SBP_hand and data.pt$SBP_machine
t = -0.46171, df = 29, p-value = 0.6477
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-3.257804 2.057804
sample estimates:
mean difference
-0.6
이번에는 사람마다 차이값을 먼저 구한 후 그것이 0인지 테스트 했고, p-value는 0.648이다.
Wilcoxon signed rank test with continuity correction
data: data.pt$SBP_hand and data.pt$SBP_machine
V = 214, p-value = 0.9482
alternative hypothesis: true location shift is not equal to 0