R4CR
Day1 - tidyverse2 | 2023-06-19
Jinhwan Kim

readr
- (로컬의) 파일을 (R로) 읽어오는 용도
- 주요 파라미터
- file, col_names
- col_types.
character,integer,number,double,logical,factor,Date,time,_,-: Skip - na: NA로 처리할 글자.
,na,999,-… - col_select : 읽을 column (
select) - skip
- n_max

readr & 3 Core function
read_csv(): Comma(,)로 구분된 데이터
read_tsv(): Tab(\t) 으로 구분된 데이터
read_table(): 공백( ) 으로 구분된 데이터
대신 쓸 수 있는 방법
- base R: read.csv(), read.delim(), read.table()
- data.table : fread()
base R vs readr
- 보통 10~100배 빠른 속도
- col_names, col_types vs header, colClasses
- date / time을 인식
- Progress bar (진행 상황 ::…)
- read_csv() vs fread()
- 데이터가 클 수록 fread()가 빠름
- delimiter, skipped row, header를 설정하지 않아도 됨
- tidyverse (tibble) 과의 연계

dplyr
- d(ata)-plyr
- 기록 시점의 데이터와 분석에 필요한 데이터는 다름
- 필요하지 않은 데이터
- (지표등을) 계산, 추가해야 하는 경우
library(dplyr)
starwars %>%
filter(species == "Droid") %>%
mutate(bmi = mass / ((height / 100) ^ 2)) %>%
select(name:mass, bmi) %>% # name 에서 mass 까지 + bmi
arrange(desc(mass)) # Decrease. desc는 %>%로 안쓰는 것이 좋음
starwars %>%
group_by(species) %>%
summarise(
n = n(), # count
mass = mean(mass, na.rm = TRUE)
) %>%
filter(
n > 1,
mass > 50
)
dplyr & 5 Core function
mutate(): 새로운 Column 추가
select(): 조건에 따라 Column 선택
filter(): 조건에 따라 Row 선택 (base R의 subset과 비슷)
group_by() & summarise(): 요약 (통계치) 계산
arrange(): Row 순서 변경 (정렬)
추가 자료: across
column들을 프로그래밍적으로 선택

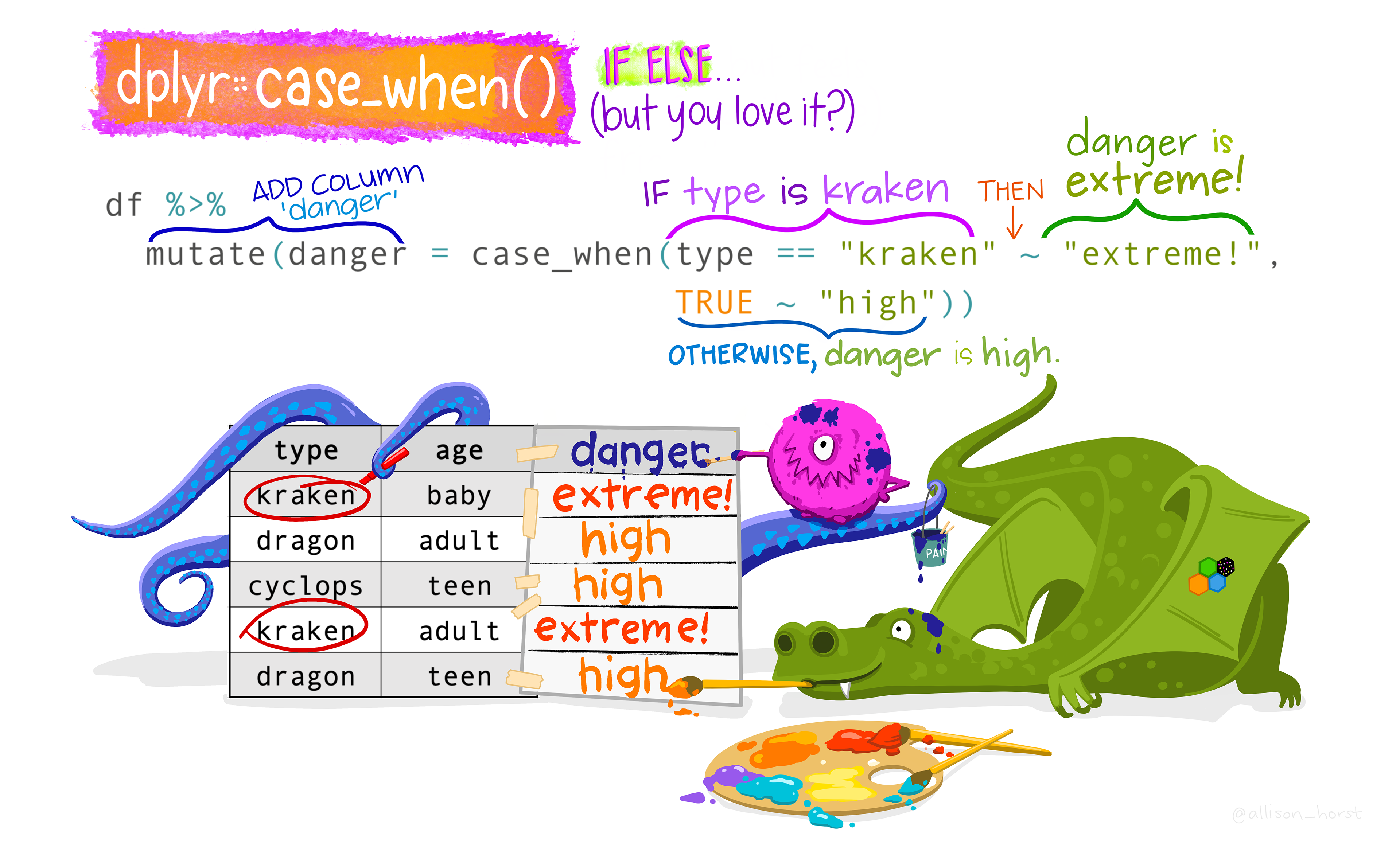
추가 자료: case_when
ifelse와 유사
추가 자료: mutate

추가 자료: relocate
column의 순서 변경

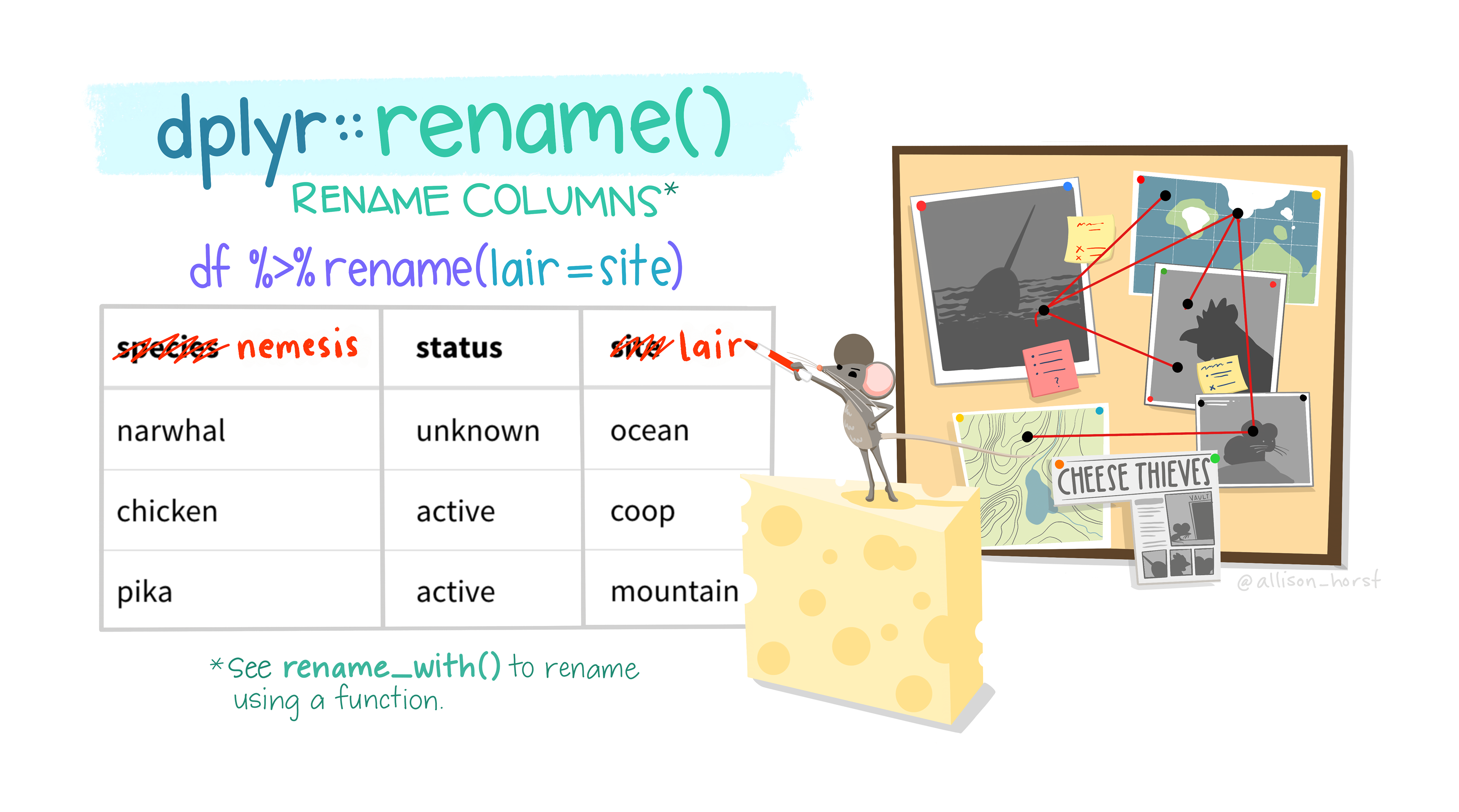
추가 자료: rename
column의 이름 변경. 자주 씀